Archiving Banking Transactions
I'm a long term user of internet banking and for a few years I've done so without paper records. This left me in the position of having no form of backup outside my bank; hardly an ideal situation. Most banks provide a way to download your transactions, usually in CSV or PDF, within a given date range. However, keeping track of the dates covered in these files is laborious and error prone.
Luckily computers are really good at this.
I've built some scripts that take a CSV of transactions, combine them with the (possibly existing) transactions locally and output a new list with all the duplicates removed. The scripts are specific to each bank so they can deal with the different data shapes produced. For instance NatWest lets you download more than one account at a time.
However, each sort-* script follows the same basic premise. Transactions are split by year then merged with any existing year files into a temporary file. This is then sorted, duplicates removed and the result is written to a <year>.csv in the appropriate account folder. All of this is done with the standard UNIX tools awk, sort, and uniq.
The NatWest script differs slightly since it must deal with multiple accounts in one file. Awk to the rescue.
These scripts are managed with Hazel watching my ~/Downloads directory for new files. Each bank has a rule tailored to its download naming scheme that runs the appropriate script before moving the file to the Trash.
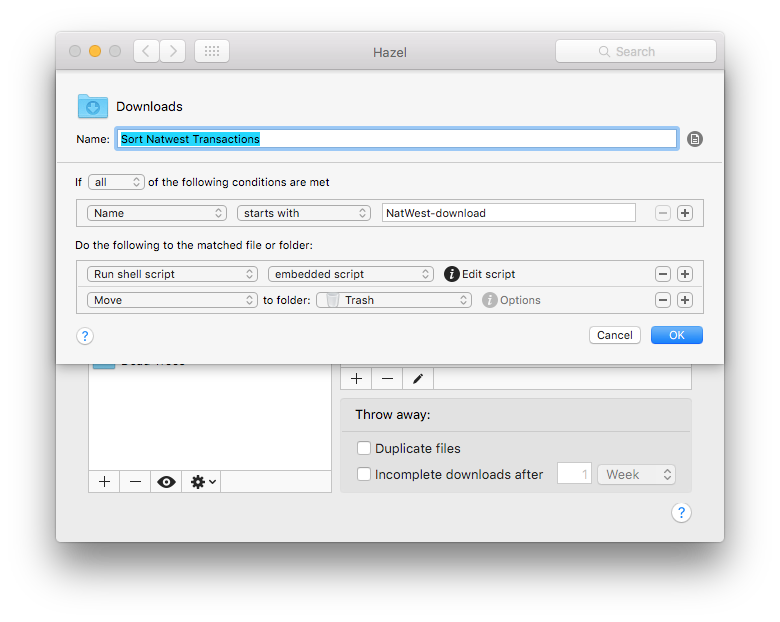
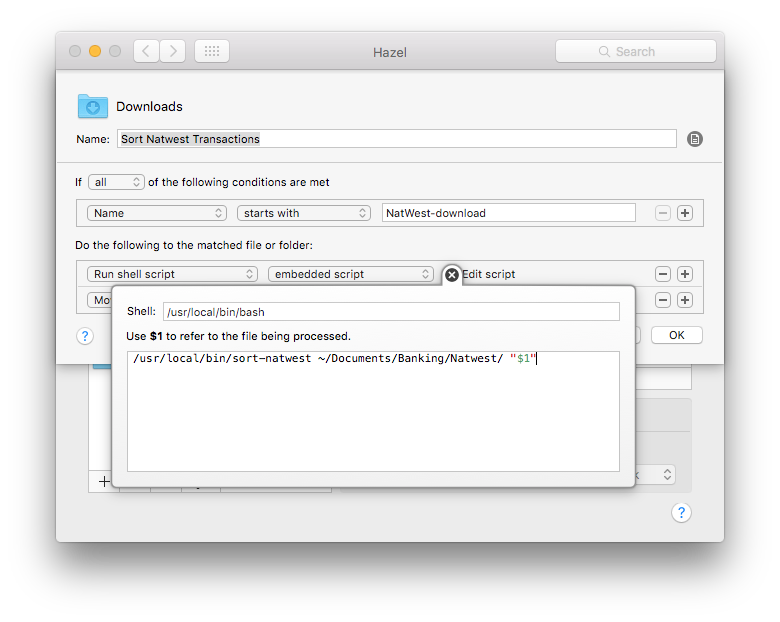
Hazel lets you pass the matched file to a script with $1 but this needs to be wrapped in quotes in case your files have spaces in them. When shell scripts interpret arguments they delimit on spaces and errors here can be hard to track down!
This is all topped off by making the scripts installable using a Homebrew tap.